Home Credit Default Risk
데이터 출처: Home Credit Default Risk
프로젝트 개요
[원문]
Many people struggle to get loans due to insufficient or non-existent credit histories. And, unfortunately, this population is often taken advantage of by untrustworthy lenders.
Home Credit Group
Home Credit strives to broaden financial inclusion for the unbanked population by providing a positive and safe borrowing experience. In order to make sure this underserved population has a positive loan experience, Home Credit makes use of a variety of alternative data–including telco and transactional information–to predict their clients’ repayment abilities.
While Home Credit is currently using various statistical and machine learning methods to make these predictions, they’re challenging Kagglers to help them unlock the full potential of their data. Doing so will ensure that clients capable of repayment are not rejected and that loans are given with a principal, maturity, and repayment calendar that will empower their clients to be successful.
[번역]
많은 사람들은 신용 기록이 불충분하거나 존재하지 않아 대출을 받기 위해 애를 씁니다. 불행히도,이 인구는 종종 신뢰할 수없는 대출 기관에 의해 이용됩니다.
주택 신용 그룹
주택 신용 기관(Home Credit)은 긍정적이고 안전한 차용 경험을 제공함으로써 비은행 인구를위한 재정적 포용을 확대하기 위해 노력합니다. 이 소외된 인구가 긍정적 인 대출 경험을 갖도록하기 위해 주택 신용 기관(Home Credit)은 고객의 상환 능력을 예측하기 위해 전화 및 거래 정보를 포함한 다양한 대체 데이터를 사용합니다.
주택 신용 기관(Home Credit)은 여러분의 다양한 통계 데이터 분석 능력과 머신러닝 방법을 활용하여, 고객이 은행 부채 상환능력에 대한 예측을 진행해 주세요. 그렇게하면 상환 가능한 고객이 거부되지 않고 성공적으로 원금, 만기 및 상환 일정에 따라 대출을 받을 수 있습니다.
프로젝트 목표
pandas,numpy,scikit-learn패키지를 활용하여 데이터 병합, 전처리, 피처 공학(feature engineering)을 진행합니다.- 데이터에 대한 시각화를 통해 주요(Key) 데이터를 추출합니다.
- 머신러닝 모델을 만들고 예측 합니다.
- Kaggle에 제출해보고, 목표 점수까지 획득할 수 있도록 수정 및 보완합니다.
프로젝트 구성
- 데이터 로드 (load data)
- 데이터 시각화 (visualization)
- 데이터 전처리 (pre-processing)
- 머신러닝을 활용하여 baseline 모델링 (modeling for baseline)
- 평가지표 생성 (evalutation)
- 모델 앙상블, 데이터 전처리 개선으로 모델의 성능을 업그레이드 하여, 목표 점수에 도달
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from IPython.display import Image
warnings.filterwarnings('ignore')
%matplotlib inline
SEED = 34
데이터 살펴보기
Image('data/home_credit.png')
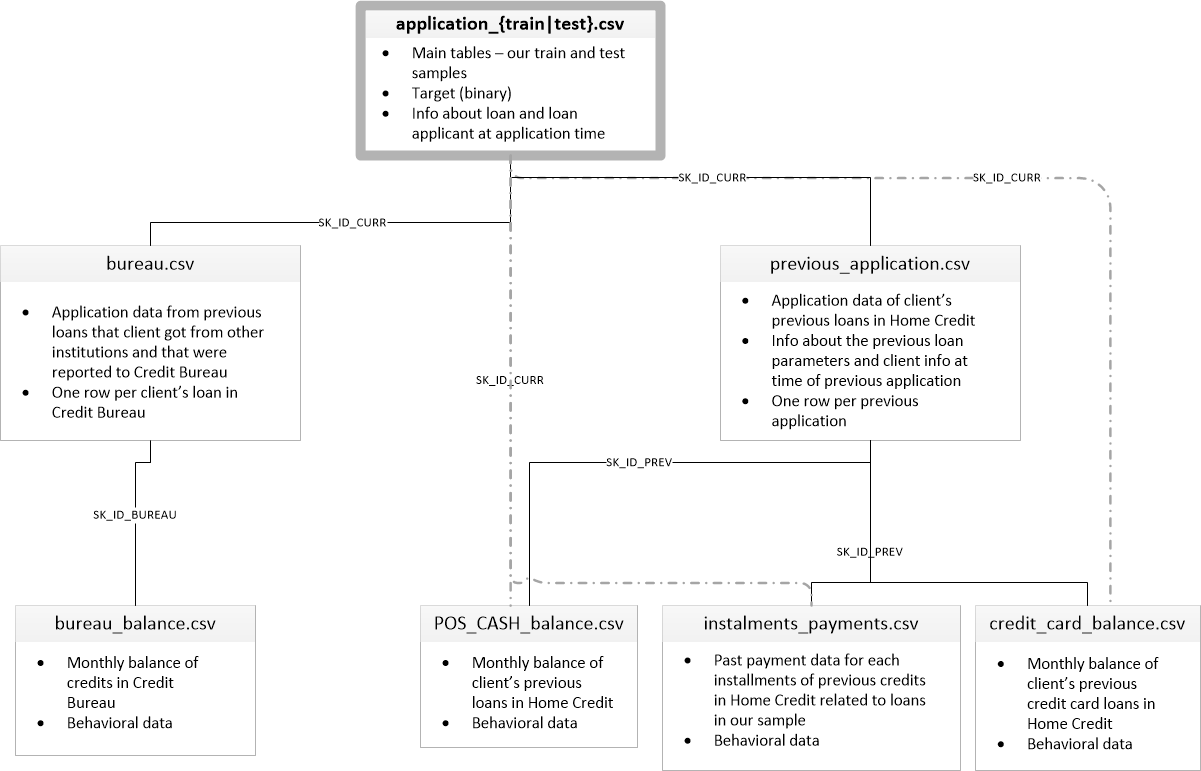
큰일입니다. 복잡한 고객의 채무관계 파악을 위해서 주택 신용 기관(Home Credit)에서 고객 정보를 여러 파일에 저장했습니다. (실제 사례에서도 당연히, 이렇게 데이터들이 산재되어 있습니다.)
우리는, 이 복잡한 데이터를 분석하기 쉽도록 하나의 데이터프레임(DataFrame) 에 merge 하는 작업과 전처리(pre-processing)하는 과정을 진행하겠습니다.
[중요]
여러 개의 파일들을 하나의 데이터프레임으로 merge 할 때, merge의 중심이 되는 ID 값이 위의 도표에 친절히 나와있습니다.
너무 걱정 마세요! 제가 예제를 한 번 보여 드리면, 쉽게 따라 하실 수 있으니깐요.
파일에 대한 설명
application_train.csv, application_test.csv
- 2개의 파일이 바로 메인이 되는 파일입니다.
- 제공되는 다른 파일 정보의 중심이 되는 데이터를 포함하고 있습니다.
- 하나의 행은 데이터 샘플에서 하나의 대출을 의미합니다.
bureau.csv
- 신용 기관 (Credit Bureau) 에 보고된 다른 금융 기관에서 제공한 모든 고객의 이전 신용 정보를 포함합니다. (고객이 이전에 대출이 있는 경우)
- 샘플의 모든 대출에는 신청 날짜 이전에 고객이 신용 관리국에 보유한 크레딧 수만큼의 행이 있습니다.
bureau_balance.csv
- 신용 기관 (Credit Bureau)에서 이전 신용의 월별 잔액을 나타냅니다.
POS_CASH_balance.csv
- 이전 POS (판매 시점) 및 신청자가 주택 신용으로 보유한 현금 대출의 월별 잔액 스냅 샷입니다.
credit_card_balance.csv
- 신청자가 주택 신용으로 보유한 이전 시용카드의 월별 잔액 스냅샷입니다.
previous_application.csv
- 샘플에 대출이있는 고객의 주택 신용 대출에 대한 모든 이전 신청.
installments_payments.csv
- 샘플의 대출과 관련하여 이전에 지불한 주택 신용에 대한 상환 내역.
Load Files
train = pd.read_csv('data/application_train.csv')
test = pd.read_csv('data/application_test.csv')
train.shape, test.shape
((307511, 122), (48744, 121))
train
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 100003 | 0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 307506 | 456251 | 0 | Cash loans | M | N | N | 0 | 157500.0 | 254700.0 | 27558.0 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 307507 | 456252 | 0 | Cash loans | F | N | Y | 0 | 72000.0 | 269550.0 | 12001.5 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 307508 | 456253 | 0 | Cash loans | F | N | Y | 0 | 153000.0 | 677664.0 | 29979.0 | ... | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 |
| 307509 | 456254 | 1 | Cash loans | F | N | Y | 0 | 171000.0 | 370107.0 | 20205.0 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 307510 | 456255 | 0 | Cash loans | F | N | N | 0 | 157500.0 | 675000.0 | 49117.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 1.0 |
307511 rows × 122 columns
TARGET 컬럼
우리가 예측해야할 label입니다.
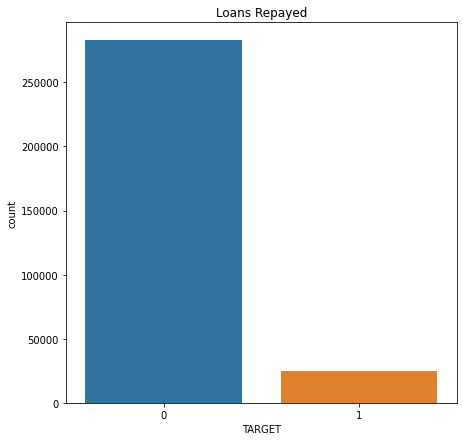
train['TARGET'].value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64
all_data라는 변수에 train 데이터와 test 데이터를 합쳐 줍니다.
전처리를 위하여 임시로 합쳐줍니다. 나중에 다시 train/test 로 분할 해야하기 때문에, 순서가 섞이면 안됩니다.
all_data = pd.concat([train, test], sort=False)
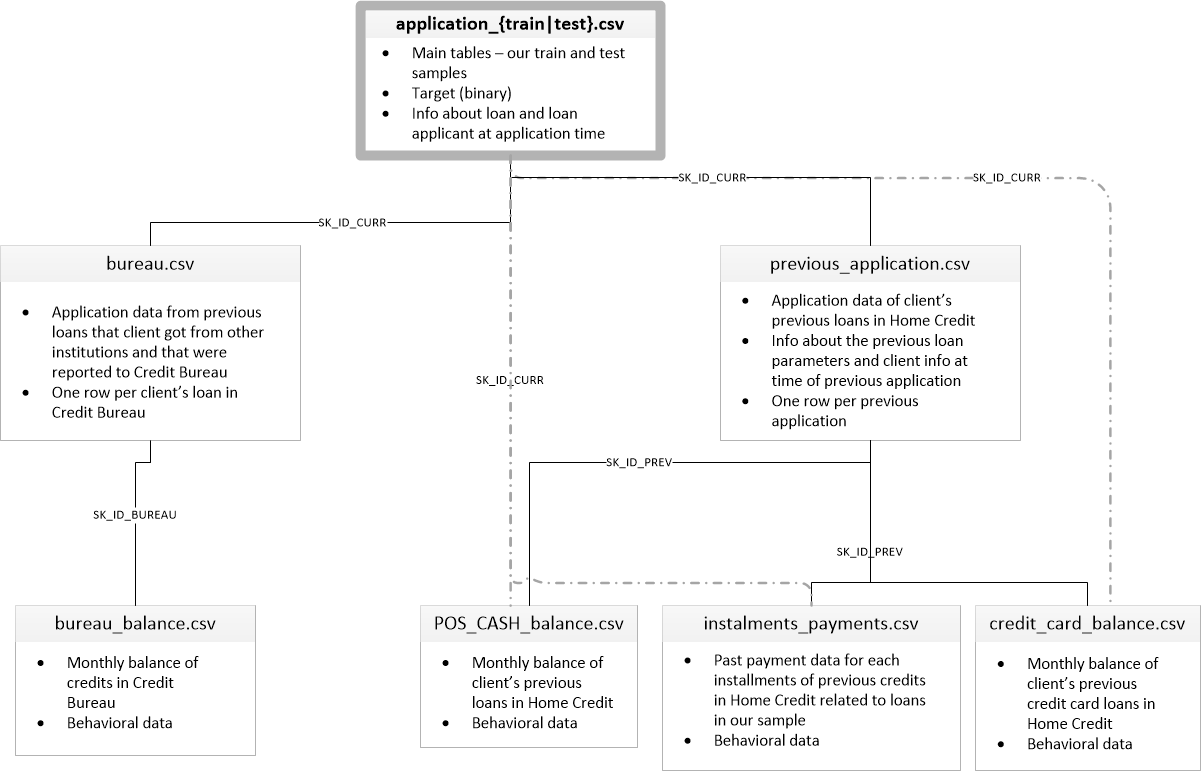
데이터 구조도
자주 데이터 구조도를 확인해가면서 전처리 작업을 진행합니다.
필요하면 별도의 창으로 띄워 놓거나, 프린트해서 보면서 풀어나가는 것도 방법입니다.
Image('data/home_credit.png')
전처리
STEP 1. Bureau & Bureau Balance 데이터 병합
bureau.csv 파일부터 차근차근 데이터를 살펴보겠습니다.
bureau = pd.read_csv('data/bureau.csv')
print(bureau.shape)
bureau.head()
(1716428, 17)
| SK_ID_CURR | SK_ID_BUREAU | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | AMT_CREDIT_MAX_OVERDUE | CNT_CREDIT_PROLONG | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_SUM_LIMIT | AMT_CREDIT_SUM_OVERDUE | CREDIT_TYPE | DAYS_CREDIT_UPDATE | AMT_ANNUITY | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 215354 | 5714462 | Closed | currency 1 | -497 | 0 | -153.0 | -153.0 | NaN | 0 | 91323.0 | 0.0 | NaN | 0.0 | Consumer credit | -131 | NaN |
| 1 | 215354 | 5714463 | Active | currency 1 | -208 | 0 | 1075.0 | NaN | NaN | 0 | 225000.0 | 171342.0 | NaN | 0.0 | Credit card | -20 | NaN |
| 2 | 215354 | 5714464 | Active | currency 1 | -203 | 0 | 528.0 | NaN | NaN | 0 | 464323.5 | NaN | NaN | 0.0 | Consumer credit | -16 | NaN |
| 3 | 215354 | 5714465 | Active | currency 1 | -203 | 0 | NaN | NaN | NaN | 0 | 90000.0 | NaN | NaN | 0.0 | Credit card | -16 | NaN |
| 4 | 215354 | 5714466 | Active | currency 1 | -629 | 0 | 1197.0 | NaN | 77674.5 | 0 | 2700000.0 | NaN | NaN | 0.0 | Consumer credit | -21 | NaN |
bureau_balance = pd.read_csv('data/bureau_balance.csv')
print(bureau_balance.shape)
bureau_balance.head()
(27299925, 3)
| SK_ID_BUREAU | MONTHS_BALANCE | STATUS | |
|---|---|---|---|
| 0 | 5715448 | 0 | C |
| 1 | 5715448 | -1 | C |
| 2 | 5715448 | -2 | C |
| 3 | 5715448 | -3 | C |
| 4 | 5715448 | -4 | C |
SK_ID_BUREAU로 bureau_balance 데이터와 bureau를 병합해주겠습니다.
하지만, bureau_balance의 SK_ID_BUREAU 키 값이 여러개 행을 포함합니다.
그렇기 때문에, 우리는 groupby를 통해 하나의 SK_ID_BUREAU에 대한 다양한 통계 정보를 bureau에 병합해주도록 하겠습니다.
right = bureau_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'] \
.agg(['sum', 'count', 'mean', 'std', 'min', 'max', 'median'])
right.head()
| sum | count | mean | std | min | max | median | |
|---|---|---|---|---|---|---|---|
| SK_ID_BUREAU | |||||||
| 5001709 | -4656 | 97 | -48.0 | 28.145456 | -96 | 0 | -48.0 |
| 5001710 | -3403 | 83 | -41.0 | 24.103942 | -82 | 0 | -41.0 |
| 5001711 | -6 | 4 | -1.5 | 1.290994 | -3 | 0 | -1.5 |
| 5001712 | -171 | 19 | -9.0 | 5.627314 | -18 | 0 | -9.0 |
| 5001713 | -231 | 22 | -10.5 | 6.493587 | -21 | 0 | -10.5 |
하나의 SK_ID_BUREAU 고유 키에 대한 다양한 통계 값으로 right 데이터프레임을 생성했습니다.
right 데이터프레임을 bureau 데이터프레임에 병합(merge) 해주도록 하겠습니다.
merged = pd.merge(bureau, right, on='SK_ID_BUREAU', how='left')
병합은 left: bureau, right: right, 기준컬럼: SK_ID_BUREAU, how:는 bureau 기준이니 left 옵션을 주도록 하였습니다.
내가 병합을 잘 했는지 안했는지 확인하는 Tip!
bureau가 합치기 전 row의 갯수와, 합친 후의 row의 갯수가 동일해야합니다. (bureau 기준으로 합쳤을 경우)
bureau.shape[0], merged.shape[0]
(1716428, 1716428)
# merge가 성공적으로 되었는지 체크 코드
# 해당 셀을 실행시 에러가 없어야 합니다.
assert bureau.shape[0] == merged.shape[0]
merged.head()
| SK_ID_CURR | SK_ID_BUREAU | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | AMT_CREDIT_MAX_OVERDUE | CNT_CREDIT_PROLONG | ... | CREDIT_TYPE | DAYS_CREDIT_UPDATE | AMT_ANNUITY | sum | count | mean | std | min | max | median | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 215354 | 5714462 | Closed | currency 1 | -497 | 0 | -153.0 | -153.0 | NaN | 0 | ... | Consumer credit | -131 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 215354 | 5714463 | Active | currency 1 | -208 | 0 | 1075.0 | NaN | NaN | 0 | ... | Credit card | -20 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 215354 | 5714464 | Active | currency 1 | -203 | 0 | 528.0 | NaN | NaN | 0 | ... | Consumer credit | -16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 215354 | 5714465 | Active | currency 1 | -203 | 0 | NaN | NaN | NaN | 0 | ... | Credit card | -16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 215354 | 5714466 | Active | currency 1 | -629 | 0 | 1197.0 | NaN | 77674.5 | 0 | ... | Consumer credit | -21 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 24 columns
동일하다면, 잘 합쳐 졌습니다!!!
STEP 2. 이제는 merged 데이터프레임을 all_data에 합쳐 보겠습니다.
merged.head()
| SK_ID_CURR | SK_ID_BUREAU | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | AMT_CREDIT_MAX_OVERDUE | CNT_CREDIT_PROLONG | ... | CREDIT_TYPE | DAYS_CREDIT_UPDATE | AMT_ANNUITY | sum | count | mean | std | min | max | median | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 215354 | 5714462 | Closed | currency 1 | -497 | 0 | -153.0 | -153.0 | NaN | 0 | ... | Consumer credit | -131 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 215354 | 5714463 | Active | currency 1 | -208 | 0 | 1075.0 | NaN | NaN | 0 | ... | Credit card | -20 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 215354 | 5714464 | Active | currency 1 | -203 | 0 | 528.0 | NaN | NaN | 0 | ... | Consumer credit | -16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 215354 | 5714465 | Active | currency 1 | -203 | 0 | NaN | NaN | NaN | 0 | ... | Credit card | -16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 215354 | 5714466 | Active | currency 1 | -629 | 0 | 1197.0 | NaN | 77674.5 | 0 | ... | Consumer credit | -21 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 24 columns
all_data.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 122 columns
SK_ID_CURR을 기준으로 합치면 유효할 것 같습니다.
all_data.shape, merged.shape
((356255, 122), (1716428, 24))
all_data를 기준으로 merged데이터프레임을 병합하되, all_data를 기준으로 병합합니다.
all_data.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 122 columns
merged.head()
| SK_ID_CURR | SK_ID_BUREAU | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | AMT_CREDIT_MAX_OVERDUE | CNT_CREDIT_PROLONG | ... | CREDIT_TYPE | DAYS_CREDIT_UPDATE | AMT_ANNUITY | sum | count | mean | std | min | max | median | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 215354 | 5714462 | Closed | currency 1 | -497 | 0 | -153.0 | -153.0 | NaN | 0 | ... | Consumer credit | -131 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 215354 | 5714463 | Active | currency 1 | -208 | 0 | 1075.0 | NaN | NaN | 0 | ... | Credit card | -20 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 215354 | 5714464 | Active | currency 1 | -203 | 0 | 528.0 | NaN | NaN | 0 | ... | Consumer credit | -16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 215354 | 5714465 | Active | currency 1 | -203 | 0 | NaN | NaN | NaN | 0 | ... | Credit card | -16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 215354 | 5714466 | Active | currency 1 | -629 | 0 | 1197.0 | NaN | 77674.5 | 0 | ... | Consumer credit | -21 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 24 columns
merged.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1716428 entries, 0 to 1716427
Data columns (total 24 columns):
SK_ID_CURR int64
SK_ID_BUREAU int64
CREDIT_ACTIVE object
CREDIT_CURRENCY object
DAYS_CREDIT int64
CREDIT_DAY_OVERDUE int64
DAYS_CREDIT_ENDDATE float64
DAYS_ENDDATE_FACT float64
AMT_CREDIT_MAX_OVERDUE float64
CNT_CREDIT_PROLONG int64
AMT_CREDIT_SUM float64
AMT_CREDIT_SUM_DEBT float64
AMT_CREDIT_SUM_LIMIT float64
AMT_CREDIT_SUM_OVERDUE float64
CREDIT_TYPE object
DAYS_CREDIT_UPDATE int64
AMT_ANNUITY float64
sum float64
count float64
mean float64
std float64
min float64
max float64
median float64
dtypes: float64(15), int64(6), object(3)
memory usage: 327.4+ MB
위의 merged 데이터 를 보면 SK_ID_CURR 컬럼에 중복 값이 들어가 있습니다.
병합할 때, SK_ID_CURR 키로 병합하게 되면, 꼬일 수 있습니다.
병합할 키 값은 항상 고유하게 유지해야합니다.
그러면, merged 데이터를 SK_ID_CURR 컬럼에 대하여 groupby 하여 수치형 데이터 / 카테고리형 데이터로 구분하여 전처리 해주도록 하겠습니다.
numerical_cols = merged.select_dtypes(exclude='object').columns.to_list()
categorical_cols = merged.select_dtypes(include='object').columns.to_list()
numerical_cols
['SK_ID_CURR',
'SK_ID_BUREAU',
'DAYS_CREDIT',
'CREDIT_DAY_OVERDUE',
'DAYS_CREDIT_ENDDATE',
'DAYS_ENDDATE_FACT',
'AMT_CREDIT_MAX_OVERDUE',
'CNT_CREDIT_PROLONG',
'AMT_CREDIT_SUM',
'AMT_CREDIT_SUM_DEBT',
'AMT_CREDIT_SUM_LIMIT',
'AMT_CREDIT_SUM_OVERDUE',
'DAYS_CREDIT_UPDATE',
'AMT_ANNUITY',
'sum',
'count',
'mean',
'std',
'min',
'max',
'median']
SK_ID_BUREAU 컬럼은 index 형 컬럼 이므로, 제거하도록 합니다. 통계 수치를 통합할 때 id 값은 제거 한 후 통계값을 산출합니다.
numerical_cols.remove('SK_ID_BUREAU')
numerical_cols
['SK_ID_CURR',
'DAYS_CREDIT',
'CREDIT_DAY_OVERDUE',
'DAYS_CREDIT_ENDDATE',
'DAYS_ENDDATE_FACT',
'AMT_CREDIT_MAX_OVERDUE',
'CNT_CREDIT_PROLONG',
'AMT_CREDIT_SUM',
'AMT_CREDIT_SUM_DEBT',
'AMT_CREDIT_SUM_LIMIT',
'AMT_CREDIT_SUM_OVERDUE',
'DAYS_CREDIT_UPDATE',
'AMT_ANNUITY',
'sum',
'count',
'mean',
'std',
'min',
'max',
'median']
categorical_cols
['CREDIT_ACTIVE', 'CREDIT_CURRENCY', 'CREDIT_TYPE']
SK_ID_CURR 키를 categorical_col 리스트에 추가 합니다. 나중에 이 키가 누락되면 병합시 키 오류가 발생합니다.
categorical_cols.append('SK_ID_CURR')
categorical_cols
['CREDIT_ACTIVE', 'CREDIT_CURRENCY', 'CREDIT_TYPE', 'SK_ID_CURR']
이제 numerical 데이터와 categorical 데이터를 각각 SK_ID_CURR로 groupby 하여 전처리를 진행하고,
numerical_right, categorical_right 변수에 임시로 데이터프레임을 저장하도록 하겠습니다.
numerical_right: 수치형 데이터 만 groupby
numerical_right = merged[numerical_cols] \
.groupby('SK_ID_CURR') \
.agg(['sum', 'count', 'mean', 'std', 'min', 'max', 'median']).reset_index()
print(numerical_right.shape)
numerical_right.head()
(305811, 134)
| SK_ID_CURR | DAYS_CREDIT | CREDIT_DAY_OVERDUE | ... | max | median | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sum | count | mean | std | min | max | median | sum | count | ... | min | max | median | sum | count | mean | std | min | max | median | ||
| 0 | 100001 | -5145 | 7 | -735.000000 | 489.942514 | -1572 | -49 | -857.0 | 0 | 7 | ... | 0.0 | 0.0 | 0.0 | -82.5 | 7 | -11.785714 | 8.025258 | -25.5 | -0.5 | -14.0 |
| 1 | 100002 | -6992 | 8 | -874.000000 | 431.451040 | -1437 | -103 | -1042.5 | 0 | 8 | ... | -32.0 | 0.0 | -18.5 | -175.0 | 8 | -21.875000 | 12.176529 | -39.5 | -1.5 | -26.0 |
| 2 | 100003 | -5603 | 4 | -1400.750000 | 909.826128 | -2586 | -606 | -1205.5 | 0 | 4 | ... | NaN | NaN | NaN | 0.0 | 0 | NaN | NaN | NaN | NaN | NaN |
| 3 | 100004 | -1734 | 2 | -867.000000 | 649.124025 | -1326 | -408 | -867.0 | 0 | 2 | ... | NaN | NaN | NaN | 0.0 | 0 | NaN | NaN | NaN | NaN | NaN |
| 4 | 100005 | -572 | 3 | -190.666667 | 162.297053 | -373 | -62 | -137.0 | 0 | 3 | ... | 0.0 | 0.0 | 0.0 | -9.0 | 3 | -3.000000 | 2.645751 | -6.0 | -1.0 | -2.0 |
5 rows × 134 columns
categorical_right: 카테고리 데이터 만 groupby
categorical_right = merged[categorical_cols] \
.groupby('SK_ID_CURR') \
.agg(['size', 'nunique']).reset_index()
print(categorical_right.shape)
categorical_right.head()
(305811, 7)
| SK_ID_CURR | CREDIT_ACTIVE | CREDIT_CURRENCY | CREDIT_TYPE | ||||
|---|---|---|---|---|---|---|---|
| size | nunique | size | nunique | size | nunique | ||
| 0 | 100001 | 7 | 2 | 7 | 1 | 7 | 1 |
| 1 | 100002 | 8 | 2 | 8 | 1 | 8 | 2 |
| 2 | 100003 | 4 | 2 | 4 | 1 | 4 | 2 |
| 3 | 100004 | 2 | 1 | 2 | 1 | 2 | 1 |
| 4 | 100005 | 3 | 2 | 3 | 1 | 3 | 2 |
Q1. all_data 기준으로 right 데이터프레임을 병합해 주세요
all_data를 기준으로 right 데이터프레임을 병합하고, all_data 변수에 다시 할당해 주세요
# 여기에 코드를 입력해 주세요 #
all_data = pd.merge(all_data, numerical_right, on='SK_ID_CURR', how='left')
all_data = pd.merge(all_data, categorical_right, on='SK_ID_CURR', how='left')
###############################
all_data.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | (median, std) | (median, min) | (median, max) | (median, median) | (CREDIT_ACTIVE, size) | (CREDIT_ACTIVE, nunique) | (CREDIT_CURRENCY, size) | (CREDIT_CURRENCY, nunique) | (CREDIT_TYPE, size) | (CREDIT_TYPE, nunique) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 12.176529 | -39.5 | -1.5 | -26.0 | 8.0 | 2.0 | 8.0 | 1.0 | 8.0 | 2.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | NaN | NaN | NaN | NaN | 4.0 | 2.0 | 4.0 | 1.0 | 4.0 | 2.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | NaN | NaN | NaN | NaN | 2.0 | 1.0 | 2.0 | 1.0 | 2.0 | 1.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | NaN | NaN | NaN | NaN | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
5 rows × 261 columns
# 검증코드
# 본 코드셀을 실행 시켜 에러가 발생하지 않아야 합니다.
assert all_data.shape == (356255, 261)
Image('data/home_credit.png')
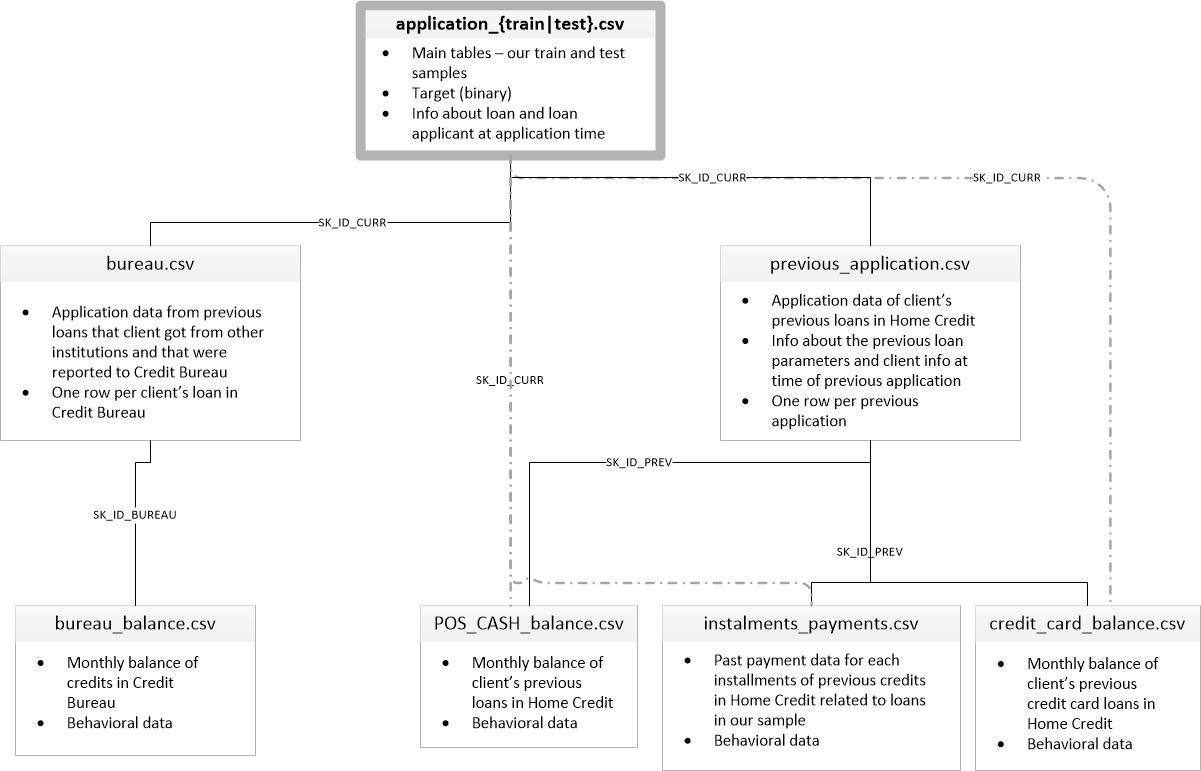
STEP 3. POS_CASH_balance 전처리 및 병합
자, 이번에는 POS_CASH_balance데이터를 all_data에 병합해보겠습니다.
pos_cash_balance = pd.read_csv('data/POS_CASH_balance.csv')
print(pos_cash_balance.shape)
pos_cash_balance.head()
(10001358, 8)
| SK_ID_PREV | SK_ID_CURR | MONTHS_BALANCE | CNT_INSTALMENT | CNT_INSTALMENT_FUTURE | NAME_CONTRACT_STATUS | SK_DPD | SK_DPD_DEF | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1803195 | 182943 | -31 | 48.0 | 45.0 | Active | 0 | 0 |
| 1 | 1715348 | 367990 | -33 | 36.0 | 35.0 | Active | 0 | 0 |
| 2 | 1784872 | 397406 | -32 | 12.0 | 9.0 | Active | 0 | 0 |
| 3 | 1903291 | 269225 | -35 | 48.0 | 42.0 | Active | 0 | 0 |
| 4 | 2341044 | 334279 | -35 | 36.0 | 35.0 | Active | 0 | 0 |
all_data.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | (median, std) | (median, min) | (median, max) | (median, median) | (CREDIT_ACTIVE, size) | (CREDIT_ACTIVE, nunique) | (CREDIT_CURRENCY, size) | (CREDIT_CURRENCY, nunique) | (CREDIT_TYPE, size) | (CREDIT_TYPE, nunique) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 12.176529 | -39.5 | -1.5 | -26.0 | 8.0 | 2.0 | 8.0 | 1.0 | 8.0 | 2.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | NaN | NaN | NaN | NaN | 4.0 | 2.0 | 4.0 | 1.0 | 4.0 | 2.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | NaN | NaN | NaN | NaN | 2.0 | 1.0 | 2.0 | 1.0 | 2.0 | 1.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | NaN | NaN | NaN | NaN | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
5 rows × 261 columns
pos_cash_balance.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10001358 entries, 0 to 10001357
Data columns (total 8 columns):
SK_ID_PREV int64
SK_ID_CURR int64
MONTHS_BALANCE int64
CNT_INSTALMENT float64
CNT_INSTALMENT_FUTURE float64
NAME_CONTRACT_STATUS object
SK_DPD int64
SK_DPD_DEF int64
dtypes: float64(2), int64(5), object(1)
memory usage: 610.4+ MB
Q2. pos_cash_balance 데이터를 SK_ID_CURR 기준으로 group 하고, 다음 6개의 column에 대하여 aggregate 합니다.
- sum, mean, std, min, max, median
- groupby 한 데이터프레임은 right 에 할당합니다.
# 여기에 코드를 입력해 주세요 #
right = pos_cash_balance.groupby(['SK_ID_CURR']) \
.agg(['sum', 'mean', 'std', 'min', 'max', 'median']).reset_index()
###############################
right.head()
| SK_ID_CURR | SK_ID_PREV | MONTHS_BALANCE | ... | SK_DPD | SK_DPD_DEF | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sum | mean | std | min | max | median | sum | mean | std | ... | std | min | max | median | sum | mean | std | min | max | median | ||
| 0 | 100001 | 14256401 | 1.584045e+06 | 254189.675833 | 1369693 | 1851984 | 1369693.0 | -653 | -72.555556 | 20.863312 | ... | 2.333333 | 0 | 7 | 0.0 | 7 | 0.777778 | 2.333333 | 0 | 7 | 0.0 |
| 1 | 100002 | 19737542 | 1.038818e+06 | 0.000000 | 1038818 | 1038818 | 1038818.0 | -190 | -10.000000 | 5.627314 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
| 2 | 100003 | 64334628 | 2.297665e+06 | 329593.011850 | 1810518 | 2636178 | 2396755.0 | -1226 | -43.785714 | 24.640162 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
| 3 | 100004 | 6256056 | 1.564014e+06 | 0.000000 | 1564014 | 1564014 | 1564014.0 | -102 | -25.500000 | 1.290994 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
| 4 | 100005 | 27452425 | 2.495675e+06 | 0.000000 | 2495675 | 2495675 | 2495675.0 | -220 | -20.000000 | 3.316625 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
5 rows × 37 columns
# 검증코드
# 본 코드셀을 실행 시켜 에러가 발생하지 않아야 합니다.
assert right.shape == (337252, 37)
all_data_2 = all_data.copy()
Q3. right 데이터프레임을 all_data에 병합합니다.
- 기준 컬럼은
SK_ID_CURR입니다. - 병합된 컬럼은 all_data에 할당합니다.
# 여기에 코드를 입력해 주세요 #
all_data = pd.merge(all_data, right, on='SK_ID_CURR', how='left')
###############################
all_data.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | (SK_DPD, std) | (SK_DPD, min) | (SK_DPD, max) | (SK_DPD, median) | (SK_DPD_DEF, sum) | (SK_DPD_DEF, mean) | (SK_DPD_DEF, std) | (SK_DPD_DEF, min) | (SK_DPD_DEF, max) | (SK_DPD_DEF, median) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 297 columns
# 검증코드
# 본 코드셀을 실행 시켜 에러가 발생하지 않아야 합니다.
assert all_data.shape == (356255, 297)
위에서 진행했던 방식과 동일한 방식으로 다른 파일에도 적용해 볼 수 있습니다.
더 높은 점수 획득을 위해서는 다양한 데이터, 많은 데이터가 있다면, 도움이 될 것 입니다.
하지만, 반복되는 코드가 많으니, 나머지는 여러분들에게 맡기겠습니다. 추가로 스스로 해보고 싶으신 분들은 다른 데이터를 병합해보는 연습을 많이 해보시길 추천합니다!
시각화
Q4. 간단한 시각화를 통해 우리가 예측해야할 데이터 샘플의 차이를 살펴 봅니다.
- 시각화 대상 컬럼:
TARGET(예측값)
데이터의 불균형도를 확인합니다.
plt.figure(figsize = (7, 7))
# 코드를 입력해 주세요
sns.countplot(x='TARGET', data=train)
plt.title('Loans Repayed')
plt.show()
문자형 컬럼에 대한 처리 (수치형 컬럼 변환)
# 카테고리형 (문자형) 컬럼만 뽑아서 보겠습니다.
cat_cols = all_data.select_dtypes(include='object').columns
all_data[cat_cols].head()
| NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | NAME_TYPE_SUITE | NAME_INCOME_TYPE | NAME_EDUCATION_TYPE | NAME_FAMILY_STATUS | NAME_HOUSING_TYPE | OCCUPATION_TYPE | WEEKDAY_APPR_PROCESS_START | ORGANIZATION_TYPE | FONDKAPREMONT_MODE | HOUSETYPE_MODE | WALLSMATERIAL_MODE | EMERGENCYSTATE_MODE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Cash loans | M | N | Y | Unaccompanied | Working | Secondary / secondary special | Single / not married | House / apartment | Laborers | WEDNESDAY | Business Entity Type 3 | reg oper account | block of flats | Stone, brick | No |
| 1 | Cash loans | F | N | N | Family | State servant | Higher education | Married | House / apartment | Core staff | MONDAY | School | reg oper account | block of flats | Block | No |
| 2 | Revolving loans | M | Y | Y | Unaccompanied | Working | Secondary / secondary special | Single / not married | House / apartment | Laborers | MONDAY | Government | NaN | NaN | NaN | NaN |
| 3 | Cash loans | F | N | Y | Unaccompanied | Working | Secondary / secondary special | Civil marriage | House / apartment | Laborers | WEDNESDAY | Business Entity Type 3 | NaN | NaN | NaN | NaN |
| 4 | Cash loans | M | N | Y | Unaccompanied | Working | Secondary / secondary special | Single / not married | House / apartment | Core staff | THURSDAY | Religion | NaN | NaN | NaN | NaN |
Q5. 카테고리형 컬럼에 대하여 LabelEncoding을 해주세요.
- 어떤 패키지/라이브러리를 활용하든 상관없습니다.
- 문자형 컬럼을 숫자형으로 인코딩합니다.
# 여기에 코드를 입력해 주세요 #
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
all_data[cat_cols] = all_data[cat_cols].astype(str)
all_data[cat_cols] = all_data[cat_cols].apply(le.fit_transform)
all_data[cat_cols].head()
###############################
# 결과 예시
all_data[cat_cols].head()
| NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | NAME_TYPE_SUITE | NAME_INCOME_TYPE | NAME_EDUCATION_TYPE | NAME_FAMILY_STATUS | NAME_HOUSING_TYPE | OCCUPATION_TYPE | WEEKDAY_APPR_PROCESS_START | ORGANIZATION_TYPE | FONDKAPREMONT_MODE | HOUSETYPE_MODE | WALLSMATERIAL_MODE | EMERGENCYSTATE_MODE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 6 | 7 | 4 | 3 | 1 | 8 | 6 | 5 | 3 | 0 | 5 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 4 | 1 | 1 | 1 | 3 | 1 | 39 | 3 | 0 | 0 | 0 |
| 2 | 1 | 1 | 1 | 1 | 6 | 7 | 4 | 3 | 1 | 8 | 1 | 11 | 0 | 1 | 7 | 2 |
| 3 | 0 | 0 | 0 | 1 | 6 | 7 | 4 | 0 | 1 | 8 | 6 | 5 | 0 | 1 | 7 | 2 |
| 4 | 0 | 1 | 0 | 1 | 6 | 7 | 4 | 3 | 1 | 3 | 4 | 37 | 0 | 1 | 7 | 2 |
다음 STEP: 빈 값(NaN)에 대한 처리를 진행합니다. 빈 값은 임의로 모든 값을 ‘0’으로 채워주겠습니다.
all_data = all_data.fillna(0)
all_data.isnull().sum()
SK_ID_CURR 0
TARGET 0
NAME_CONTRACT_TYPE 0
CODE_GENDER 0
FLAG_OWN_CAR 0
..
(SK_DPD_DEF, mean) 0
(SK_DPD_DEF, std) 0
(SK_DPD_DEF, min) 0
(SK_DPD_DEF, max) 0
(SK_DPD_DEF, median) 0
Length: 297, dtype: int64
train / test 의 데이터를 분할합니다.
train_data = all_data[:len(train)]
test_data = all_data[len(train):]
test_data = test_data.drop('TARGET', 1)
# 검증코드
assert train_data.shape[0] == train.shape[0]
# 검증코드
assert test_data.shape[0] == test.shape[0]
train_data, test_data로 분할해 주었습니다. 이제는 검증세트까지 만들어 보겠습니다.
Q6. train_test_split 을 활용하여, 데이터를 분할해 주세요
train_test_split()의 다음 2개의 파라미터에 대하여 고정 값으로 입력해 주세요
from sklearn.model_selection import train_test_split
random_state=34
test_size=0.2
# 여기에 코드를 입력해 주세요 #
x_train, x_valid, y_train, y_valid = train_test_split(#코드 입력
train_data.drop('TARGET', 1),
train_data['TARGET'],
stratify=train_data['TARGET'],
random_state=random_state,
test_size=test_size)
###############################
모델링
from sklearn.ensemble import RandomForestClassifier
Q7. RandomForestClassifier 앙상블 모델을 활용하여 모델을 학습합니다.
# 코드를 입력해 주세요 #
model = RandomForestClassifier(n_estimators=500, max_depth=6, n_jobs=-1)
random_forest_model_fitted = model.fit(x_train, y_train)
########################
아래 코드는 각각의 상위 20개의 모델 예측에 영향을 준 feature들을 살펴봅니다.
importance가 높을 수록 모델 예측에 많은 기여가 되는 컬럼입니다.
fi = pd.DataFrame(list(zip(x_train.columns, model.feature_importances_))).sort_values(by=1, ascending=False).reset_index(drop=True).head(20)
fi.columns = ['feature', 'importance']
fi
| feature | importance | |
|---|---|---|
| 0 | EXT_SOURCE_2 | 0.160928 |
| 1 | EXT_SOURCE_3 | 0.115736 |
| 2 | EXT_SOURCE_1 | 0.039500 |
| 3 | (DAYS_CREDIT, median) | 0.031559 |
| 4 | (DAYS_CREDIT, mean) | 0.031123 |
| 5 | DAYS_BIRTH | 0.028970 |
| 6 | (DAYS_CREDIT_UPDATE, median) | 0.020913 |
| 7 | (DAYS_CREDIT, max) | 0.017683 |
| 8 | NAME_EDUCATION_TYPE | 0.015948 |
| 9 | (DAYS_CREDIT_ENDDATE, median) | 0.015230 |
| 10 | (DAYS_CREDIT_UPDATE, mean) | 0.014170 |
| 11 | NAME_INCOME_TYPE | 0.014002 |
| 12 | DAYS_EMPLOYED | 0.011659 |
| 13 | (DAYS_CREDIT_ENDDATE, sum) | 0.011387 |
| 14 | (SK_DPD_DEF, mean) | 0.011383 |
| 15 | AMT_GOODS_PRICE | 0.010654 |
| 16 | (DAYS_CREDIT_ENDDATE, mean) | 0.010363 |
| 17 | (AMT_CREDIT_MAX_OVERDUE, max) | 0.010264 |
| 18 | (AMT_CREDIT_MAX_OVERDUE, sum) | 0.009801 |
| 19 | (DAYS_CREDIT, min) | 0.009569 |
이번 대회에서는 제출 기준을 TARGET이 1이 될 확률을 제출하는 것입니다.
predict() 함수는 class를 예측해주지만, predict_proba()는 각각의 class에 대한 확률값을 return합니다.
우리는 1이될 확률을 구해야합니다.
pred = model.predict_proba(test_data)
# 1이 될 확률을 구합니다.
pred[:, 1]
array([0.08281809, 0.12250228, 0.05997663, ..., 0.06619179, 0.05734652,
0.10617588])
sample_submission 파일에 우리가 예측한 정답값을 입력합니다.
submission = pd.read_csv('data/sample_submission.csv')
# 정답 입력
submission['TARGET'] = pred[:, 1]
submission.head()
| SK_ID_CURR | TARGET | |
|---|---|---|
| 0 | 100001 | 0.082818 |
| 1 | 100005 | 0.122502 |
| 2 | 100013 | 0.059977 |
| 3 | 100028 | 0.047601 |
| 4 | 100038 | 0.123701 |
submission 파일을 csv 포맷의 파일로 내보냅니다.
대부분의 Kaggle 대회에서는 csv 파일 제출을 요구합니다.
from datetime import datetime
timestring = datetime.now().strftime('%m-%d-%H-%M-%S')
filename = '{}-homecredit-submit.csv'.format(timestring)
submission.to_csv(filename, index=False)
이제 날짜와 시간이 입혀진 정답 파일(.csv)이 나왔습니다.
Late Submission을 해보고, 우리의 점수가 리더보드에 어느 수준인지 확인합니다.
제출은 이곳에서 Late Submission 클릭 후 - 자신이 예측한 모델의 예측값이 들어있는 .csv 파일 업로드 - 제출
Extra Q. 전처리, 모델 변경 등을 통해서 더 나은 예측 모델을 만들어서 캐글 상위권에 도전합니다 (0.73 이상)
hint: RandomForestClassifier 단일 모델로도 0.73 이상 달성할 수 있습니다. 다만, hyperparameter를 튜닝해야합니다.
- max_features, max_depth, n_estimators를 유심히 살펴보세요
- 도큐먼트
# 이곳에 코드를 입력해 주세요
model_2 = RandomForestClassifier(n_estimators=100,
max_features=0.2,
max_depth=8,
n_jobs=-1)
random_forest_model_fitted_2 = model_2.fit(x_train, y_train)
final_pred_2 = model_2.predict_proba(test_data)
submission = pd.read_csv('data/sample_submission.csv')
# 정답 입력
submission['TARGET'] = final_pred_2[:, 1]
# submission 파일 생성
timestring = datetime.now().strftime('%m-%d-%H-%M-%S')
filename = '{}-homecredit-submit.csv'.format(timestring)
submission.to_csv(filename, index=False)
아래 추가로 코드 작성 해봤으나 만족할 만한 결과는 나오지 않았습니다.
all_data_2.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | (median, std) | (median, min) | (median, max) | (median, median) | (CREDIT_ACTIVE, size) | (CREDIT_ACTIVE, nunique) | (CREDIT_CURRENCY, size) | (CREDIT_CURRENCY, nunique) | (CREDIT_TYPE, size) | (CREDIT_TYPE, nunique) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 12.176529 | -39.5 | -1.5 | -26.0 | 8.0 | 2.0 | 8.0 | 1.0 | 8.0 | 2.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | NaN | NaN | NaN | NaN | 4.0 | 2.0 | 4.0 | 1.0 | 4.0 | 2.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | NaN | NaN | NaN | NaN | 2.0 | 1.0 | 2.0 | 1.0 | 2.0 | 1.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | NaN | NaN | NaN | NaN | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
5 rows × 261 columns
# pos_cash_balance 데이터를 SK_ID_CURR 기준으로 group
# 수치형 데이터 / 카테고리형 데이터로 구분하여 전처리
numerical_cols = pos_cash_balance.select_dtypes(exclude='object').columns.to_list()
categorical_cols = pos_cash_balance.select_dtypes(include='object').columns.to_list()
numerical_cols
['SK_ID_PREV',
'SK_ID_CURR',
'MONTHS_BALANCE',
'CNT_INSTALMENT',
'CNT_INSTALMENT_FUTURE',
'SK_DPD',
'SK_DPD_DEF']
# SK_ID_PREV 제거
numerical_cols.remove('SK_ID_PREV')
numerical_cols
['SK_ID_CURR',
'MONTHS_BALANCE',
'CNT_INSTALMENT',
'CNT_INSTALMENT_FUTURE',
'SK_DPD',
'SK_DPD_DEF']
categorical_cols
['NAME_CONTRACT_STATUS']
# SK_ID_CURR 추가
categorical_cols.append('SK_ID_CURR')
categorical_cols
['NAME_CONTRACT_STATUS', 'SK_ID_CURR']
numerical_right = pos_cash_balance[numerical_cols] \
.groupby(['SK_ID_CURR']) \
.agg(['sum', 'mean', 'std', 'min', 'max', 'median']).reset_index()
print(numerical_right.shape)
numerical_right.head()
(337252, 31)
| SK_ID_CURR | MONTHS_BALANCE | CNT_INSTALMENT | ... | SK_DPD | SK_DPD_DEF | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sum | mean | std | min | max | median | sum | mean | std | ... | std | min | max | median | sum | mean | std | min | max | median | ||
| 0 | 100001 | -653 | -72.555556 | 20.863312 | -96 | -53 | -57.0 | 36.0 | 4.000000 | 0.000000 | ... | 2.333333 | 0 | 7 | 0.0 | 7 | 0.777778 | 2.333333 | 0 | 7 | 0.0 |
| 1 | 100002 | -190 | -10.000000 | 5.627314 | -19 | -1 | -10.0 | 456.0 | 24.000000 | 0.000000 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
| 2 | 100003 | -1226 | -43.785714 | 24.640162 | -77 | -18 | -26.5 | 283.0 | 10.107143 | 2.806597 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
| 3 | 100004 | -102 | -25.500000 | 1.290994 | -27 | -24 | -25.5 | 15.0 | 3.750000 | 0.500000 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
| 4 | 100005 | -220 | -20.000000 | 3.316625 | -25 | -15 | -20.0 | 117.0 | 11.700000 | 0.948683 | ... | 0.000000 | 0 | 0 | 0.0 | 0 | 0.000000 | 0.000000 | 0 | 0 | 0.0 |
5 rows × 31 columns
categorical_right = pos_cash_balance[categorical_cols] \
.groupby('SK_ID_CURR') \
.agg(['size', 'nunique']).reset_index()
print(categorical_right.shape)
categorical_right.head()
(337252, 3)
| SK_ID_CURR | NAME_CONTRACT_STATUS | ||
|---|---|---|---|
| size | nunique | ||
| 0 | 100001 | 9 | 2 |
| 1 | 100002 | 19 | 1 |
| 2 | 100003 | 28 | 2 |
| 3 | 100004 | 4 | 2 |
| 4 | 100005 | 11 | 3 |
all_data_2 = pd.merge(all_data_2, numerical_right, on='SK_ID_CURR', how='left')
all_data_2 = pd.merge(all_data_2, categorical_right, on='SK_ID_CURR', how='left')
all_data_2.shape
(356255, 293)
all_data_2.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | (SK_DPD, max) | (SK_DPD, median) | (SK_DPD_DEF, sum) | (SK_DPD_DEF, mean) | (SK_DPD_DEF, std) | (SK_DPD_DEF, min) | (SK_DPD_DEF, max) | (SK_DPD_DEF, median) | (NAME_CONTRACT_STATUS, size) | (NAME_CONTRACT_STATUS, nunique) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 19.0 | 1.0 |
| 1 | 100003 | 0.0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 28.0 | 2.0 |
| 2 | 100004 | 0.0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 4.0 | 2.0 |
| 3 | 100006 | 0.0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 21.0 | 3.0 |
| 4 | 100007 | 0.0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 66.0 | 3.0 |
5 rows × 293 columns
all_data_2.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 356255 entries, 0 to 356254
Columns: 293 entries, SK_ID_CURR to (NAME_CONTRACT_STATUS, nunique)
dtypes: float64(237), int64(40), object(16)
memory usage: 799.1+ MB
# 카테고리형 col 중 속성값이 2개 이하인 데이터는 label 인코딩
# 2개 이상인 데이터는 one hot encoding 진행
le = LabelEncoder()
le_count = 0
# Iterate through the columns
for col in all_data_2:
if all_data_2[col].dtype == 'object':
# If 2 or fewer unique categories
if len(list(all_data_2[col].unique())) <= 2:
# Train on the training data
le.fit(all_data_2[col])
# Transform both training and testing data
all_data_2[col] = le.transform(all_data_2[col])
# Keep track of how many columns were label encoded
le_count += 1
print('%d columns were label encoded.' % le_count)
3 columns were label encoded.
# 2개 이상인 데이터는 one hot encoding 진행
all_data_2 = pd.get_dummies(all_data_2)
display(all_data_2.shape)
(356255, 414)
def missing_values_table(df):
mis_val = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum() / len(df)
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
print ("The dataset has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
return mis_val_table_ren_columns
missing_values_table(all_data_2)
The dataset has 414 columns.
There are 233 columns that have missing values.
| Missing Values | % of Total Values | |
|---|---|---|
| (AMT_ANNUITY, std) | 263856 | 74.1 |
| COMMONAREA_MODE | 248360 | 69.7 |
| COMMONAREA_MEDI | 248360 | 69.7 |
| COMMONAREA_AVG | 248360 | 69.7 |
| NONLIVINGAPARTMENTS_MODE | 246861 | 69.3 |
| ... | ... | ... |
| EXT_SOURCE_2 | 668 | 0.2 |
| AMT_GOODS_PRICE | 278 | 0.1 |
| AMT_ANNUITY | 36 | 0.0 |
| CNT_FAM_MEMBERS | 2 | 0.0 |
| DAYS_LAST_PHONE_CHANGE | 1 | 0.0 |
233 rows × 2 columns
# 카테고리형 (문자형) 컬럼만 뽑아서 보겠습니다.
num_cols = all_data_2.select_dtypes(exclude='object').columns
all_data_2[num_cols].head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | AMT_GOODS_PRICE | ... | HOUSETYPE_MODE_terraced house | WALLSMATERIAL_MODE_Block | WALLSMATERIAL_MODE_Mixed | WALLSMATERIAL_MODE_Monolithic | WALLSMATERIAL_MODE_Others | WALLSMATERIAL_MODE_Panel | WALLSMATERIAL_MODE_Stone, brick | WALLSMATERIAL_MODE_Wooden | EMERGENCYSTATE_MODE_No | EMERGENCYSTATE_MODE_Yes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1.0 | 0 | 0 | 1 | 0 | 202500.0 | 406597.5 | 24700.5 | 351000.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 100003 | 0.0 | 0 | 0 | 0 | 0 | 270000.0 | 1293502.5 | 35698.5 | 1129500.0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 100004 | 0.0 | 1 | 1 | 1 | 0 | 67500.0 | 135000.0 | 6750.0 | 135000.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 100006 | 0.0 | 0 | 0 | 1 | 0 | 135000.0 | 312682.5 | 29686.5 | 297000.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 100007 | 0.0 | 0 | 0 | 1 | 0 | 121500.0 | 513000.0 | 21865.5 | 513000.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 414 columns
for col in all_data_2[num_cols]:
print(col, all_data_2[col].isna().sum())
SK_ID_CURR 0
TARGET 48744
NAME_CONTRACT_TYPE 0
FLAG_OWN_CAR 0
FLAG_OWN_REALTY 0
CNT_CHILDREN 0
AMT_INCOME_TOTAL 0
AMT_CREDIT 0
AMT_ANNUITY 36
AMT_GOODS_PRICE 278
REGION_POPULATION_RELATIVE 0
DAYS_BIRTH 0
DAYS_EMPLOYED 0
DAYS_REGISTRATION 0
DAYS_ID_PUBLISH 0
OWN_CAR_AGE 235241
FLAG_MOBIL 0
FLAG_EMP_PHONE 0
FLAG_WORK_PHONE 0
FLAG_CONT_MOBILE 0
FLAG_PHONE 0
FLAG_EMAIL 0
CNT_FAM_MEMBERS 2
REGION_RATING_CLIENT 0
REGION_RATING_CLIENT_W_CITY 0
HOUR_APPR_PROCESS_START 0
REG_REGION_NOT_LIVE_REGION 0
REG_REGION_NOT_WORK_REGION 0
LIVE_REGION_NOT_WORK_REGION 0
REG_CITY_NOT_LIVE_CITY 0
REG_CITY_NOT_WORK_CITY 0
LIVE_CITY_NOT_WORK_CITY 0
EXT_SOURCE_1 193910
EXT_SOURCE_2 668
EXT_SOURCE_3 69633
APARTMENTS_AVG 179948
BASEMENTAREA_AVG 207584
YEARS_BEGINEXPLUATATION_AVG 172863
YEARS_BUILD_AVG 236306
COMMONAREA_AVG 248360
ELEVATORS_AVG 189080
ENTRANCES_AVG 178407
FLOORSMAX_AVG 176341
FLOORSMIN_AVG 241108
LANDAREA_AVG 210844
LIVINGAPARTMENTS_AVG 242979
LIVINGAREA_AVG 177902
NONLIVINGAPARTMENTS_AVG 246861
NONLIVINGAREA_AVG 195766
APARTMENTS_MODE 179948
BASEMENTAREA_MODE 207584
YEARS_BEGINEXPLUATATION_MODE 172863
YEARS_BUILD_MODE 236306
COMMONAREA_MODE 248360
ELEVATORS_MODE 189080
ENTRANCES_MODE 178407
FLOORSMAX_MODE 176341
FLOORSMIN_MODE 241108
LANDAREA_MODE 210844
LIVINGAPARTMENTS_MODE 242979
LIVINGAREA_MODE 177902
NONLIVINGAPARTMENTS_MODE 246861
NONLIVINGAREA_MODE 195766
APARTMENTS_MEDI 179948
BASEMENTAREA_MEDI 207584
YEARS_BEGINEXPLUATATION_MEDI 172863
YEARS_BUILD_MEDI 236306
COMMONAREA_MEDI 248360
ELEVATORS_MEDI 189080
ENTRANCES_MEDI 178407
FLOORSMAX_MEDI 176341
FLOORSMIN_MEDI 241108
LANDAREA_MEDI 210844
LIVINGAPARTMENTS_MEDI 242979
LIVINGAREA_MEDI 177902
NONLIVINGAPARTMENTS_MEDI 246861
NONLIVINGAREA_MEDI 195766
TOTALAREA_MODE 171055
OBS_30_CNT_SOCIAL_CIRCLE 1050
DEF_30_CNT_SOCIAL_CIRCLE 1050
OBS_60_CNT_SOCIAL_CIRCLE 1050
DEF_60_CNT_SOCIAL_CIRCLE 1050
DAYS_LAST_PHONE_CHANGE 1
FLAG_DOCUMENT_2 0
FLAG_DOCUMENT_3 0
FLAG_DOCUMENT_4 0
FLAG_DOCUMENT_5 0
FLAG_DOCUMENT_6 0
FLAG_DOCUMENT_7 0
FLAG_DOCUMENT_8 0
FLAG_DOCUMENT_9 0
FLAG_DOCUMENT_10 0
FLAG_DOCUMENT_11 0
FLAG_DOCUMENT_12 0
FLAG_DOCUMENT_13 0
FLAG_DOCUMENT_14 0
FLAG_DOCUMENT_15 0
FLAG_DOCUMENT_16 0
FLAG_DOCUMENT_17 0
FLAG_DOCUMENT_18 0
FLAG_DOCUMENT_19 0
FLAG_DOCUMENT_20 0
FLAG_DOCUMENT_21 0
AMT_REQ_CREDIT_BUREAU_HOUR 47568
AMT_REQ_CREDIT_BUREAU_DAY 47568
AMT_REQ_CREDIT_BUREAU_WEEK 47568
AMT_REQ_CREDIT_BUREAU_MON 47568
AMT_REQ_CREDIT_BUREAU_QRT 47568
AMT_REQ_CREDIT_BUREAU_YEAR 47568
('DAYS_CREDIT', 'sum') 50444
('DAYS_CREDIT', 'count') 50444
('DAYS_CREDIT', 'mean') 50444
('DAYS_CREDIT', 'std') 91964
('DAYS_CREDIT', 'min') 50444
('DAYS_CREDIT', 'max') 50444
('DAYS_CREDIT', 'median') 50444
('CREDIT_DAY_OVERDUE', 'sum') 50444
('CREDIT_DAY_OVERDUE', 'count') 50444
('CREDIT_DAY_OVERDUE', 'mean') 50444
('CREDIT_DAY_OVERDUE', 'std') 91964
('CREDIT_DAY_OVERDUE', 'min') 50444
('CREDIT_DAY_OVERDUE', 'max') 50444
('CREDIT_DAY_OVERDUE', 'median') 50444
('DAYS_CREDIT_ENDDATE', 'sum') 50444
('DAYS_CREDIT_ENDDATE', 'count') 50444
('DAYS_CREDIT_ENDDATE', 'mean') 53029
('DAYS_CREDIT_ENDDATE', 'std') 97343
('DAYS_CREDIT_ENDDATE', 'min') 53029
('DAYS_CREDIT_ENDDATE', 'max') 53029
('DAYS_CREDIT_ENDDATE', 'median') 53029
('DAYS_ENDDATE_FACT', 'sum') 50444
('DAYS_ENDDATE_FACT', 'count') 50444
('DAYS_ENDDATE_FACT', 'mean') 88100
('DAYS_ENDDATE_FACT', 'std') 149639
('DAYS_ENDDATE_FACT', 'min') 88100
('DAYS_ENDDATE_FACT', 'max') 88100
('DAYS_ENDDATE_FACT', 'median') 88100
('AMT_CREDIT_MAX_OVERDUE', 'sum') 50444
('AMT_CREDIT_MAX_OVERDUE', 'count') 50444
('AMT_CREDIT_MAX_OVERDUE', 'mean') 143284
('AMT_CREDIT_MAX_OVERDUE', 'std') 219686
('AMT_CREDIT_MAX_OVERDUE', 'min') 143284
('AMT_CREDIT_MAX_OVERDUE', 'max') 143284
('AMT_CREDIT_MAX_OVERDUE', 'median') 143284
('CNT_CREDIT_PROLONG', 'sum') 50444
('CNT_CREDIT_PROLONG', 'count') 50444
('CNT_CREDIT_PROLONG', 'mean') 50444
('CNT_CREDIT_PROLONG', 'std') 91964
('CNT_CREDIT_PROLONG', 'min') 50444
('CNT_CREDIT_PROLONG', 'max') 50444
('CNT_CREDIT_PROLONG', 'median') 50444
('AMT_CREDIT_SUM', 'sum') 50444
('AMT_CREDIT_SUM', 'count') 50444
('AMT_CREDIT_SUM', 'mean') 50446
('AMT_CREDIT_SUM', 'std') 91965
('AMT_CREDIT_SUM', 'min') 50446
('AMT_CREDIT_SUM', 'max') 50446
('AMT_CREDIT_SUM', 'median') 50446
('AMT_CREDIT_SUM_DEBT', 'sum') 50444
('AMT_CREDIT_SUM_DEBT', 'count') 50444
('AMT_CREDIT_SUM_DEBT', 'mean') 58816
('AMT_CREDIT_SUM_DEBT', 'std') 107105
('AMT_CREDIT_SUM_DEBT', 'min') 58816
('AMT_CREDIT_SUM_DEBT', 'max') 58816
('AMT_CREDIT_SUM_DEBT', 'median') 58816
('AMT_CREDIT_SUM_LIMIT', 'sum') 50444
('AMT_CREDIT_SUM_LIMIT', 'count') 50444
('AMT_CREDIT_SUM_LIMIT', 'mean') 75752
('AMT_CREDIT_SUM_LIMIT', 'std') 134454
('AMT_CREDIT_SUM_LIMIT', 'min') 75752
('AMT_CREDIT_SUM_LIMIT', 'max') 75752
('AMT_CREDIT_SUM_LIMIT', 'median') 75752
('AMT_CREDIT_SUM_OVERDUE', 'sum') 50444
('AMT_CREDIT_SUM_OVERDUE', 'count') 50444
('AMT_CREDIT_SUM_OVERDUE', 'mean') 50444
('AMT_CREDIT_SUM_OVERDUE', 'std') 91964
('AMT_CREDIT_SUM_OVERDUE', 'min') 50444
('AMT_CREDIT_SUM_OVERDUE', 'max') 50444
('AMT_CREDIT_SUM_OVERDUE', 'median') 50444
('DAYS_CREDIT_UPDATE', 'sum') 50444
('DAYS_CREDIT_UPDATE', 'count') 50444
('DAYS_CREDIT_UPDATE', 'mean') 50444
('DAYS_CREDIT_UPDATE', 'std') 91964
('DAYS_CREDIT_UPDATE', 'min') 50444
('DAYS_CREDIT_UPDATE', 'max') 50444
('DAYS_CREDIT_UPDATE', 'median') 50444
('AMT_ANNUITY', 'sum') 50444
('AMT_ANNUITY', 'count') 50444
('AMT_ANNUITY', 'mean') 238031
('AMT_ANNUITY', 'std') 263856
('AMT_ANNUITY', 'min') 238031
('AMT_ANNUITY', 'max') 238031
('AMT_ANNUITY', 'median') 238031
('sum', 'sum') 50444
('sum', 'count') 50444
('sum', 'mean') 221713
('sum', 'std') 239353
('sum', 'min') 221713
('sum', 'max') 221713
('sum', 'median') 221713
('count', 'sum') 50444
('count', 'count') 50444
('count', 'mean') 221713
('count', 'std') 239353
('count', 'min') 221713
('count', 'max') 221713
('count', 'median') 221713
('mean', 'sum') 50444
('mean', 'count') 50444
('mean', 'mean') 221713
('mean', 'std') 239353
('mean', 'min') 221713
('mean', 'max') 221713
('mean', 'median') 221713
('std', 'sum') 50444
('std', 'count') 50444
('std', 'mean') 222002
('std', 'std') 239751
('std', 'min') 222002
('std', 'max') 222002
('std', 'median') 222002
('min', 'sum') 50444
('min', 'count') 50444
('min', 'mean') 221713
('min', 'std') 239353
('min', 'min') 221713
('min', 'max') 221713
('min', 'median') 221713
('max', 'sum') 50444
('max', 'count') 50444
('max', 'mean') 221713
('max', 'std') 239353
('max', 'min') 221713
('max', 'max') 221713
('max', 'median') 221713
('median', 'sum') 50444
('median', 'count') 50444
('median', 'mean') 221713
('median', 'std') 239353
('median', 'min') 221713
('median', 'max') 221713
('median', 'median') 221713
('CREDIT_ACTIVE', 'size') 50444
('CREDIT_ACTIVE', 'nunique') 50444
('CREDIT_CURRENCY', 'size') 50444
('CREDIT_CURRENCY', 'nunique') 50444
('CREDIT_TYPE', 'size') 50444
('CREDIT_TYPE', 'nunique') 50444
('MONTHS_BALANCE', 'sum') 19003
('MONTHS_BALANCE', 'mean') 19003
('MONTHS_BALANCE', 'std') 19375
('MONTHS_BALANCE', 'min') 19003
('MONTHS_BALANCE', 'max') 19003
('MONTHS_BALANCE', 'median') 19003
('CNT_INSTALMENT', 'sum') 19003
('CNT_INSTALMENT', 'mean') 19031
('CNT_INSTALMENT', 'std') 19397
('CNT_INSTALMENT', 'min') 19031
('CNT_INSTALMENT', 'max') 19031
('CNT_INSTALMENT', 'median') 19031
('CNT_INSTALMENT_FUTURE', 'sum') 19003
('CNT_INSTALMENT_FUTURE', 'mean') 19031
('CNT_INSTALMENT_FUTURE', 'std') 19397
('CNT_INSTALMENT_FUTURE', 'min') 19031
('CNT_INSTALMENT_FUTURE', 'max') 19031
('CNT_INSTALMENT_FUTURE', 'median') 19031
('SK_DPD', 'sum') 19003
('SK_DPD', 'mean') 19003
('SK_DPD', 'std') 19375
('SK_DPD', 'min') 19003
('SK_DPD', 'max') 19003
('SK_DPD', 'median') 19003
('SK_DPD_DEF', 'sum') 19003
('SK_DPD_DEF', 'mean') 19003
('SK_DPD_DEF', 'std') 19375
('SK_DPD_DEF', 'min') 19003
('SK_DPD_DEF', 'max') 19003
('SK_DPD_DEF', 'median') 19003
('NAME_CONTRACT_STATUS', 'size') 19003
('NAME_CONTRACT_STATUS', 'nunique') 19003
CODE_GENDER_F 0
CODE_GENDER_M 0
CODE_GENDER_XNA 0
NAME_TYPE_SUITE_Children 0
NAME_TYPE_SUITE_Family 0
NAME_TYPE_SUITE_Group of people 0
NAME_TYPE_SUITE_Other_A 0
NAME_TYPE_SUITE_Other_B 0
NAME_TYPE_SUITE_Spouse, partner 0
NAME_TYPE_SUITE_Unaccompanied 0
NAME_INCOME_TYPE_Businessman 0
NAME_INCOME_TYPE_Commercial associate 0
NAME_INCOME_TYPE_Maternity leave 0
NAME_INCOME_TYPE_Pensioner 0
NAME_INCOME_TYPE_State servant 0
NAME_INCOME_TYPE_Student 0
NAME_INCOME_TYPE_Unemployed 0
NAME_INCOME_TYPE_Working 0
NAME_EDUCATION_TYPE_Academic degree 0
NAME_EDUCATION_TYPE_Higher education 0
NAME_EDUCATION_TYPE_Incomplete higher 0
NAME_EDUCATION_TYPE_Lower secondary 0
NAME_EDUCATION_TYPE_Secondary / secondary special 0
NAME_FAMILY_STATUS_Civil marriage 0
NAME_FAMILY_STATUS_Married 0
NAME_FAMILY_STATUS_Separated 0
NAME_FAMILY_STATUS_Single / not married 0
NAME_FAMILY_STATUS_Unknown 0
NAME_FAMILY_STATUS_Widow 0
NAME_HOUSING_TYPE_Co-op apartment 0
NAME_HOUSING_TYPE_House / apartment 0
NAME_HOUSING_TYPE_Municipal apartment 0
NAME_HOUSING_TYPE_Office apartment 0
NAME_HOUSING_TYPE_Rented apartment 0
NAME_HOUSING_TYPE_With parents 0
OCCUPATION_TYPE_Accountants 0
OCCUPATION_TYPE_Cleaning staff 0
OCCUPATION_TYPE_Cooking staff 0
OCCUPATION_TYPE_Core staff 0
OCCUPATION_TYPE_Drivers 0
OCCUPATION_TYPE_HR staff 0
OCCUPATION_TYPE_High skill tech staff 0
OCCUPATION_TYPE_IT staff 0
OCCUPATION_TYPE_Laborers 0
OCCUPATION_TYPE_Low-skill Laborers 0
OCCUPATION_TYPE_Managers 0
OCCUPATION_TYPE_Medicine staff 0
OCCUPATION_TYPE_Private service staff 0
OCCUPATION_TYPE_Realty agents 0
OCCUPATION_TYPE_Sales staff 0
OCCUPATION_TYPE_Secretaries 0
OCCUPATION_TYPE_Security staff 0
OCCUPATION_TYPE_Waiters/barmen staff 0
WEEKDAY_APPR_PROCESS_START_FRIDAY 0
WEEKDAY_APPR_PROCESS_START_MONDAY 0
WEEKDAY_APPR_PROCESS_START_SATURDAY 0
WEEKDAY_APPR_PROCESS_START_SUNDAY 0
WEEKDAY_APPR_PROCESS_START_THURSDAY 0
WEEKDAY_APPR_PROCESS_START_TUESDAY 0
WEEKDAY_APPR_PROCESS_START_WEDNESDAY 0
ORGANIZATION_TYPE_Advertising 0
ORGANIZATION_TYPE_Agriculture 0
ORGANIZATION_TYPE_Bank 0
ORGANIZATION_TYPE_Business Entity Type 1 0
ORGANIZATION_TYPE_Business Entity Type 2 0
ORGANIZATION_TYPE_Business Entity Type 3 0
ORGANIZATION_TYPE_Cleaning 0
ORGANIZATION_TYPE_Construction 0
ORGANIZATION_TYPE_Culture 0
ORGANIZATION_TYPE_Electricity 0
ORGANIZATION_TYPE_Emergency 0
ORGANIZATION_TYPE_Government 0
ORGANIZATION_TYPE_Hotel 0
ORGANIZATION_TYPE_Housing 0
ORGANIZATION_TYPE_Industry: type 1 0
ORGANIZATION_TYPE_Industry: type 10 0
ORGANIZATION_TYPE_Industry: type 11 0
ORGANIZATION_TYPE_Industry: type 12 0
ORGANIZATION_TYPE_Industry: type 13 0
ORGANIZATION_TYPE_Industry: type 2 0
ORGANIZATION_TYPE_Industry: type 3 0
ORGANIZATION_TYPE_Industry: type 4 0
ORGANIZATION_TYPE_Industry: type 5 0
ORGANIZATION_TYPE_Industry: type 6 0
ORGANIZATION_TYPE_Industry: type 7 0
ORGANIZATION_TYPE_Industry: type 8 0
ORGANIZATION_TYPE_Industry: type 9 0
ORGANIZATION_TYPE_Insurance 0
ORGANIZATION_TYPE_Kindergarten 0
ORGANIZATION_TYPE_Legal Services 0
ORGANIZATION_TYPE_Medicine 0
ORGANIZATION_TYPE_Military 0
ORGANIZATION_TYPE_Mobile 0
ORGANIZATION_TYPE_Other 0
ORGANIZATION_TYPE_Police 0
ORGANIZATION_TYPE_Postal 0
ORGANIZATION_TYPE_Realtor 0
ORGANIZATION_TYPE_Religion 0
ORGANIZATION_TYPE_Restaurant 0
ORGANIZATION_TYPE_School 0
ORGANIZATION_TYPE_Security 0
ORGANIZATION_TYPE_Security Ministries 0
ORGANIZATION_TYPE_Self-employed 0
ORGANIZATION_TYPE_Services 0
ORGANIZATION_TYPE_Telecom 0
ORGANIZATION_TYPE_Trade: type 1 0
ORGANIZATION_TYPE_Trade: type 2 0
ORGANIZATION_TYPE_Trade: type 3 0
ORGANIZATION_TYPE_Trade: type 4 0
ORGANIZATION_TYPE_Trade: type 5 0
ORGANIZATION_TYPE_Trade: type 6 0
ORGANIZATION_TYPE_Trade: type 7 0
ORGANIZATION_TYPE_Transport: type 1 0
ORGANIZATION_TYPE_Transport: type 2 0
ORGANIZATION_TYPE_Transport: type 3 0
ORGANIZATION_TYPE_Transport: type 4 0
ORGANIZATION_TYPE_University 0
ORGANIZATION_TYPE_XNA 0
FONDKAPREMONT_MODE_not specified 0
FONDKAPREMONT_MODE_org spec account 0
FONDKAPREMONT_MODE_reg oper account 0
FONDKAPREMONT_MODE_reg oper spec account 0
HOUSETYPE_MODE_block of flats 0
HOUSETYPE_MODE_specific housing 0
HOUSETYPE_MODE_terraced house 0
WALLSMATERIAL_MODE_Block 0
WALLSMATERIAL_MODE_Mixed 0
WALLSMATERIAL_MODE_Monolithic 0
WALLSMATERIAL_MODE_Others 0
WALLSMATERIAL_MODE_Panel 0
WALLSMATERIAL_MODE_Stone, brick 0
WALLSMATERIAL_MODE_Wooden 0
EMERGENCYSTATE_MODE_No 0
EMERGENCYSTATE_MODE_Yes 0
all_data_Encoding = all_data_2.fillna(0)
missing_values_table(all_data_Encoding)
The dataset has 414 columns.
There are 0 columns that have missing values.
| Missing Values | % of Total Values |
|---|
# 피처 스케일링
from sklearn.preprocessing import MinMaxScaler
def encoder(df):
scaler = MinMaxScaler()
numerical = all_data_Encoding.select_dtypes(exclude = ["object"]).columns
features_transform = pd.DataFrame(data= df)
features_transform[numerical] = scaler.fit_transform(df[numerical])
display(features_transform.head(n = 5))
return df
all_data_scale = encoder(all_data_Encoding)
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | AMT_GOODS_PRICE | ... | HOUSETYPE_MODE_terraced house | WALLSMATERIAL_MODE_Block | WALLSMATERIAL_MODE_Mixed | WALLSMATERIAL_MODE_Monolithic | WALLSMATERIAL_MODE_Others | WALLSMATERIAL_MODE_Panel | WALLSMATERIAL_MODE_Stone, brick | WALLSMATERIAL_MODE_Wooden | EMERGENCYSTATE_MODE_No | EMERGENCYSTATE_MODE_Yes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000003 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.001512 | 0.090287 | 0.095729 | 0.086667 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 1 | 0.000006 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.002089 | 0.311736 | 0.138353 | 0.278889 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 0.000008 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.000358 | 0.022472 | 0.026160 | 0.033333 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.000014 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.000935 | 0.066837 | 0.115053 | 0.073333 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.000017 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.000819 | 0.116854 | 0.084742 | 0.126667 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 414 columns
# 다중공선성 검정
corrs = all_data_scale.corr()
threshold = 0.8
above_threshold_vars = {}
for col in corrs:
above_threshold_vars[col] = list(corrs.index[corrs[col]> threshold])
len(above_threshold_vars)
414
cols_to_remove = []
cols_seen = []
cols_to_remove_pair = []
for key, value in above_threshold_vars.items():
cols_seen.append(key)
for x in value :
if x == key:
next
else:
if x not in cols_seen:
cols_to_remove.append(x)
cols_to_remove_pair.append(key)
cols_to_remove = list(set(cols_to_remove))
all_data_removed = all_data_scale.drop(columns=cols_to_remove)
all_data_removed.shape
(356255, 266)
train_data_1 = all_data_removed[:len(train)]
test_data_1 = all_data_removed[len(train):]
test_data_1 = test_data_1.drop('TARGET', 1)
# 검증코드
assert train_data_1.shape[0] == train.shape[0]
# 검증코드
assert test_data_1.shape[0] == test.shape[0]
# 여기에 코드를 입력해 주세요 #
x_train, x_valid, y_train, y_valid = train_test_split(#코드 입력
train_data_1.drop('TARGET', 1),
train_data_1['TARGET'],
stratify=train_data_1['TARGET'],
random_state=random_state,
test_size=test_size)
# 기존의 X_train, y_train, X_test, y_test의 형태 확인
print("Number transactions x_train dataset: ", x_train.shape)
print("Number transactions y_train dataset: ", y_train.shape)
print("Number transactions x_valid dataset: ", x_valid.shape)
print("Number transactions y_valid dataset: ", y_valid.shape)
Number transactions x_train dataset: (246008, 265)
Number transactions y_train dataset: (246008,)
Number transactions x_valid dataset: (61503, 265)
Number transactions y_valid dataset: (61503,)
# SMOTE을 이용해서 Oversampling
from imblearn.over_sampling import SMOTE
print("Before OverSampling, counts of label '1': {}".format(sum(y_train == 1))) # y_train 중 레이블 값이 1인 데이터의 개수
print("Before OverSampling, counts of label '0': {} \n".format(sum(y_train == 0))) # y_train 중 레이블 값이 0 인 데이터의 개수
sm = SMOTE(random_state = 42, ratio = 0.3) # SMOTE 알고리즘, 비율 증가
X_train_res, y_train_res = sm.fit_sample(x_train, y_train.ravel()) # Over Sampling 진행
print("After OverSampling, counts of label '1': {}".format(sum(y_train_res==1)))
print("After OverSampling, counts of label '0': {}".format(sum(y_train_res==0)))
Before OverSampling, counts of label '1': 19860
Before OverSampling, counts of label '0': 226148
After OverSampling, counts of label '1': 67844
After OverSampling, counts of label '0': 226148
print("Before OverSampling, the shape of x_train: {}".format(x_train.shape)) # SMOTE 적용 이전 데이터 형태
print("Before OverSampling, the shape of y_train: {}".format(y_train.shape)) # SMOTE 적용 이전 데이터 형태
print('After OverSampling, the shape of X_train_res: {}'.format(X_train_res.shape)) # SMOTE 적용 결과 확인
print('After OverSampling, the shape of y_train_res: {}'.format(y_train_res.shape)) # # SMOTE 적용 결과 확인
Before OverSampling, the shape of x_train: (246008, 265)
Before OverSampling, the shape of y_train: (246008,)
After OverSampling, the shape of X_train_res: (293992, 265)
After OverSampling, the shape of y_train_res: (293992,)
# 이곳에 코드를 입력해 주세요
model_3 = RandomForestClassifier(n_estimators=100,
max_features=0.2,
max_depth=8,
n_jobs=-1)
random_forest_model_fitted_3 = model_3.fit(X_train_res, y_train_res)
final_pred_3 = model_3.predict_proba(test_data_1)
submission = pd.read_csv('data/sample_submission.csv')
# 정답 입력
submission['TARGET'] = final_pred_3[:, 1]
# submission 파일 생성
timestring = datetime.now().strftime('%m-%d-%H-%M-%S')
filename = '{}-homecredit-submit.csv'.format(timestring)
submission.to_csv(filename, index=False)